两个研究小组都聚焦于TSK模糊系统下的迁移学习,因此仔细研究一下 TSK Fuzzy system 下的 Transfer learning。
文章附图,挺复杂的,暂时没看懂: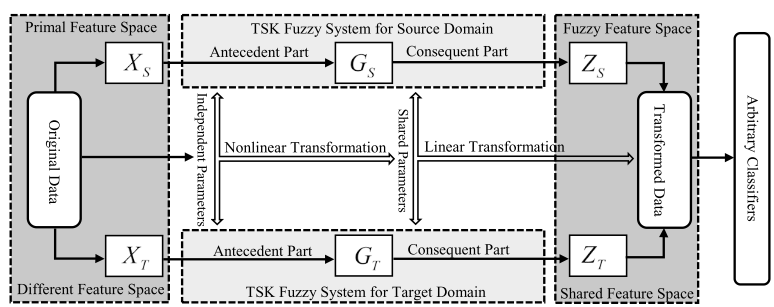
TSK Fuzzy Logis System
TSK模糊模型由一组简单的模糊推理规则构成:
其中$x_{j},(j=1,2, \dots, d)$下标是输入的第$j$个维度,$d$是输入的总维度,$K$是模糊规则的总数量。$f^{k}(\boldsymbol{x})$是第$k$个模糊规则下的输出。输入空间上的模糊集$A^{k} \subset R^{d}$被映射到输出空间上$f^{k}(x) \subset R$上。$\wedge$是模糊并运算。请注意这个$f^{k}(x)$只是一个模糊规则的输出,二TSK是多个模糊规则下的输出:
式中$\mu^{k}(\mathbf{x})$是模糊集$A^{k}$的隶属度值,$\tilde{\mu}^{k}(\mathbf{x})$是正则化之后的隶属度。请注意模糊集$A^{k}$的维度是$d$,$\mathbf{X}$的隶属度是每个维度的隶属度的乘积:
其中$\mathbf{X}$每个维度的隶属度值可以由有多种模型,如三角隶属度或者高斯隶属度。此处选择高斯隶属度:
高斯隶属度的中心值$c_{i}^{k}$和宽度值$\delta_{i}^{k}$可以由多种方法确定,此处选择Fuzzy c-means方法求解。这个方法程序可以轻松在网上找到。两个参数可以表示为:
式中$u_{j k}$是值第$k$个聚类下的第$j$个样本的隶属度。$N$是样本总数量。TSK加上FCM算法下,聚类中心的数量即为模糊规则的数量。$h$是模型超参数,可以用交叉验证等策略确定。
经过以上过程得到训练数据的隶属度之后,多个维度的隶属度为每个维度隶属度相乘:
隶属度函数正则化:
此时FS的输出是:
到此隶属度虽然有了,但是每个$f^{k}(x)$中仍有未知参数$p_{d}^{k}$。
接着,FS的输出可以简化为:
其中输入加上偏置:
每个子规则的输入乘隶属度,之后再乘线性模型参数p,以下处理只是为了计算方便:
经过以上处理之后,$\mathbf{X}_{g}$即为经过Fuzzy 映射之后的特征向量,其实就是原数据乘以隶属度,文中称作:_the antecedent part of TSK-FS_ 。 而后面的参数部分$\mathbf{p}_{g}$文中称作:_the consequent parameters of the TSK-FS_ 。此时由于隶属度全是已知的,式子(6)其实是一个线性模型,在输入给定时,可以用最小二乘法求解$\mathbf{p}_{g}$。
Maximum Mean Discrepency
文中又回顾了以下最大均值偏差,这里不详细说了:
迁移学习的目的是求解$\phi$。[_这么说勉强也可以_]
然后作者觉得需要同时对齐边缘和条件分布,因此采用了清华龙组的JDA方法,首先边缘和条件分布分别表示为:
这里对于条件分布的表示略微奇怪,不过没关系,先继续看。其中$C$是分类问题对应的总类别。$n_{s}^{(c)}$是原数据中对应于类别$c$的样本的个数。目标数据集的伪标签是基于原数据训练的,初始伪标签精度较低,后续会不断迭代,这些在JDA方法中都有,我先继续看看作者还要做什么。
Overview of TRL-TSK-FS
Transfer representation learning - TSK- Fuzzy system. 为了在缩小分布距离的同时保证数据结构,目标函数定义如下:
Shared Feature Space Construction
_通常构建特征空间的方式为:首先非线性变换,再降维 — 作者_
文章的创新思路在于对于 _the antecedent part_ 做非线性变换,再对 _the consequent part_ 做降维。
回顾以下,前者是指乘了隶属度之后的训练样本,后者参数是线性子模型的参数p,这里把多输出TSK-FS的输出当作了是输出特征,因此本文其实是把MO-TSK-FS当作了自编码器,。
Fuzzy feature space based on TSK-FS
源数据和目标数据上的单个样本分别表示为:
整个源数据集和目标数据集表示为:
模型参数P此处乘以了m,整个FS变成了多输出FS:
本来FS是一个向量$\mathbf{x}$映射到一个$y$数字,现在变成了一个向量$\mathbf{x}$映射到m个数字$y$,于是多输出的FS变成了一个从向量$\mathbf{x}$到向量$\mathbf{y}$的映射,如果后者的维度低于前者,那么就可以当作是一种降维提取高级特征。我觉得这种方法优点问题
继续看,对于一个样本$\boldsymbol{g}_{s_{i}}$,映射表示为:
对于整组源数据和目标数据,映射可以表示为:
疑问:一般特征表示及降维,所得到的特征是正交的。而这里多输出很有可能多个模糊输出是相同的
文中这里假设源数据和目标数据都服从一组参数P,也就是服从相同的线性模糊模型
总结:文章认为,源数据和目标数据的隶属度是不同的,而模糊规则是相同的,翻译成文中的话就是,前参数相同,而后参数是不同的。源数据和目标数据的前参数[中心值和宽度值]可以通过FCM求解。而后参数则是基于JDA的方法优化。
Antecedent parameters (前参数即隶属度等)
FCM 虽然常用,但是却不稳定,对参数非常敏感,此处使用了 Var-Part聚类方法。用于得到前参数中的聚类中心和聚类宽度,从而计算隶属度。
T. Su and J. G. Dy, "In search of deterministic methods for initializing K-means and Gaussian mixture clustering," Intelligent Data Analysis, vol. 11, pp. 319-338, 2007
Distribution Matching
此处开始用JDA的方法,因此简写:
最小化边缘分布:
最小化条件分布:
总优化目标即为:
式10需要求解映射$\phi$,而式17只需要求解线性映射P,这就是本文的创新,其实优点像TCA文中,也不求解映射,只是假设是某种映射。
保持数据几何结构
这部分其实就是TCA中用到的,最大化中心矩阵方差的形式,保持数据结构:
其中$\mathbf{H}_{T}$是中心矩阵。
同时考虑the discriminant information,作者又丰富了目标函数,这个我没见过,可能是一种常用的保持数据类别结构的方法吧:
联合优化目标
$\alpha, \beta$ and $\lambda$是正则化参数,与JDA求解相似,转成约束优化问题:
上式可以用拉格朗日方程表示为:
其中$\Phi=\operatorname{diag}\left(\varphi_{1}, \varphi_{2}, \cdots, \varphi_{m}\right) \in R^{m \times m}$是拉格朗日乘子,使$\frac{\partial L}{\partial \mathbf{P}}=0$可得:
到这里是个广义特征值分解问题,可以用matlab的eigs直接求解了!
计算复杂度
刚好JDA文章有计算复杂度分析,这里完全复刻过来就行。
总结
本文的创新在于,利用模糊模型做假设:源数据和目标数据仅隶属度不同,而模糊规则相同。不管这种假设是否成立,这毕竟是一种新的思路。很棒。
[1]Yang C, Deng Z, Choi K S, et al. Takagi–Sugeno–Kang transfer learning fuzzy logic system for the adaptive recognition of epileptic electroencephalogram signals[J]. IEEE Transactions on Fuzzy Systems, 2016, 24(5): 1079-1094.
[2] Zuo H, Zhang G, Pedrycz W, et al. Fuzzy regression transfer learning in Takagi–Sugeno fuzzy models[J]. IEEE Transactions on Fuzzy Systems, 2017, 25(6): 1795-1807.
[3] Xu P, Deng Z, Wang J, et al. Transfer Representation Learning with TSK Fuzzy System[J]. arXiv preprint arXiv:1901.02703, 2019.